
From Prompt to Code Part 1: Inside the Gemini CLI's Execution Engine
Most new tools get a blog post explaining their features. This isn't one of them. This is the first in a series of developer-to-developer looks under the hood of the Gemini CLI.

In this first post, we'll explore how Gemini CLI thinks, processes requests, and ultimately writes code. We're not just going to see what it can do; we're going to dive into the source code to understand how its capabilities are engineered.
The Core Engine: How it Thinks
The functionality of the Gemini CLI lies in its ability to use tools. When you ask it to "summarize README.md," it doesn't just guess. It knows it needs to read the file. This entire process is orchestrated by an event-driven core loop that transforms your natural language into executable actions.
This journey is a conversation between the model and your local machine. At the heart of this is the Turn class in packages/core/src/core/turn.ts:
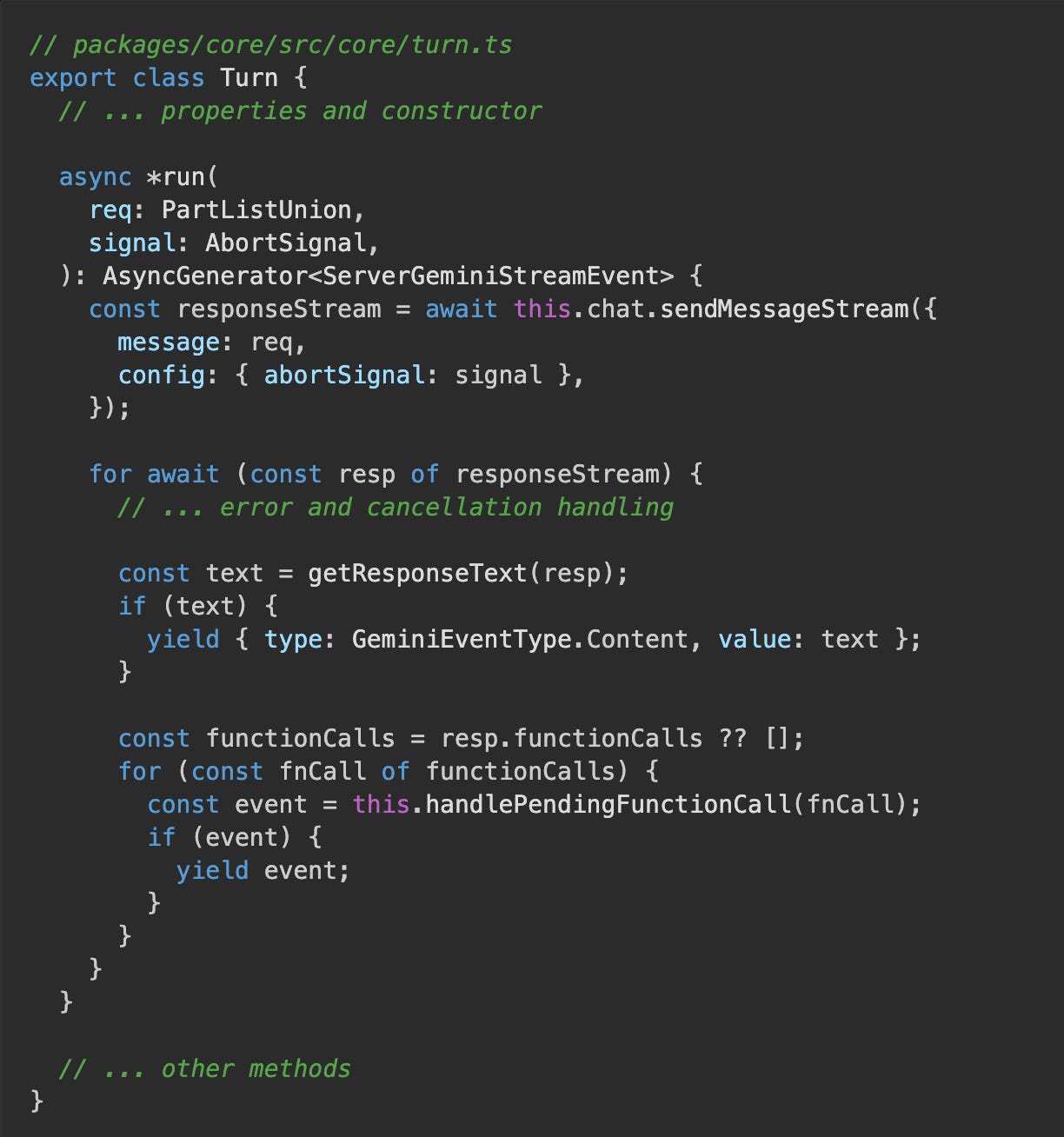
Its run method is an async generator that iterates over the stream from the Gemini API, yielding events for each piece of information received.
On the client side, the useGeminiStream hook in packages/cli/src/ui/hooks/useGeminiStream.ts consumes these events:

It listens to the stream and reacts based on the event type, collecting tool call requests along the way.
Once the model has finished its response, the collected toolCallRequests are handed off to the CoreToolScheduler from packages/core/src/core/coreToolScheduler.ts:

It manages the entire lifecycle of tool execution—from validation and user confirmation to running the tool and returning the result. This event-driven architecture is what makes the Gemini CLI so interactive.
Tool Execution: Concurrency is Key
An interesting aspect of the CLI's design is how it handles multiple tool requests from the model. It does not execute them sequentially. For efficiency, it runs them all concurrently.
The CoreToolScheduler in packages/core/src/core/coreToolScheduler.ts is responsible for this:

When it receives a list of tools to execute, it iterates through them and starts each one without waiting for the previous one to finish. The scheduler then waits for all of these concurrent operations to complete. Once every tool has finished, it bundles all of their results into a single, consolidated response that is sent back to the Gemini model in the next turn.
Anatomy of a Code Change: From Prompt to Verified Code
Here is a diagram illustrating the entire flow from a user's prompt to the final, verified code change:

Gemini CLI's ability to write and modify code is its most powerful feature. It's a multi-step, methodical process guided by the main system prompt in packages/core/src/core/prompts.ts. Let's trace the entire lifecycle for a common request.
User Prompt: "Add a
getUserByIdfunction tosrc/api.tsthat returns a user object."
Here is the step-by-step breakdown of what happens internally
Step 1: Understand the Context

Gemini CLI first needs to understand the code it's about to modify. It won't make assumptions about the file content.
Model's Thought Process: "I need to read the file
src/api.tsto understand its current structure and conventions before I can add a new function."Action: The model issues a tool call to read the file. This is managed by the
TurnandGeminiChatclasses.
[tool_code: read_file(absolute_path="/path/to/project/src/api.ts")]
Step 2: Formulating a Plan

This is where the power of the system prompt in packages/core/src/core/prompts.ts becomes evident. There isn't a separate, hardcoded prompt template for generating a plan. Instead, the agent's behavior emerges from the instructions it was given at the start of the session.
The system prompt in packages/core/src/core/prompts.ts contains the following instruction:
// packages/core/src/core/prompts.ts
2. **Plan:** Build a coherent and grounded (based on the understanding in step 1) plan for how you intend to resolve the user's task. Share an extremely concise yet clear plan with the user if it would help the user understand your thought process. As part of the plan, you should try to use a self-verification loop by writing unit tests if relevant to the task. Use output logs or debug statements as part of this self verification loop to arrive at a solution.After the read_file tool returns the content of src/api.ts, that content is added to the conversation history.
The model now has all the necessary context:
The user's original request ("Add a
getUserByIdfunction...").The full content of the file to be modified.
The system-level instruction to create and share a plan before acting.
Model's Thought Process: "I have read the file. My instructions say to create a plan now. Based on the user's request and the file content, I will propose adding a new function."
Action: The model's next response is a simple text response containing the plan, which is then displayed to the user.
I will add a new function
getUserByIdtosrc/api.ts. It will accept a user ID and return a sample user object.
This emergent, instruction-following behavior is more flexible and powerful than a rigid, template-based system.
Step 3: Generate and Apply the Code

This is where the agentic behavior shines. Once the user approves, the CLI doesn't just ask the model to "add the function." It uses the conversational history, which now contains the file content, to generate the precise code change.
The model generates just the new function snippet. Then, the CLI agent constructs a call to the edit tool with:
old_string: A large, unique block of the original file where the new code should be inserted.new_string: The exact same block asold_string, but with the newly generated code snippet inserted in the correct place.

The key to the EditTool's ( in packages/core/src/tools/edit.ts) reliability is the calculateEdit method. Internally, it calls ensureCorrectEdit (from packages/core/src/utils/editCorrector.ts), a function that makes the process robust. If the old_string provided by the model doesn't perfectly match the file's content (perhaps due to manual edits or slightly out of date context) ensureCorrectEdit uses an LLM call to intelligently locate the correct insertion point. This self-correction prevents the entire operation from failing due to small discrepancies.
Step 4: Verify the Change

A good developer verifies their work and the Gemini CLI's system prompt encourages this behavior. After a successful file modification, the agent's job isn't over.
Model's Thought Process: "The code has been added. Now I should run the project's linter and type-checker to ensure I haven't introduced any errors."
Action: The model issues another tool call, this time to the
shelltool.
[tool_code: shell(command="npm run lint && npm run typecheck")]
Gemini CLI executes this command, and the output is sent back to the model. If the checks pass, it can confidently report that the task is complete.
This "understand, plan, generate, execute, and verify" loop is what makes the Gemini CLI a true developer partner, not just a text generator.
Next Up
The Agent's Memory and Toolkit. We've seen how the Gemini CLI thinks, but how does it remember and act? In Part 2, we'll explore the multi-layered memory system that makes the agent truly context-aware, from project-level instructions to on-the-fly file loading. We'll also dissect some of its most powerful tools, like the edit tool, to see how they work under the hood.