
From Prompt to Code Part 2: Inside Gemini CLI's Memory and Tools
This is the second post in our developer-focused series on the Gemini CLI. In Part 1, we explored code generation. Now, we'll look at how Gemini CLI remembers information and uses its tools.

How Gemini CLI Remembers
A good assistant remembers what you've told it. Gemini CLI has a multi-layered system for managing context.
The @ Command and On-the-Fly Context
When you use the @ command (e.g., @src/components), you're implicitly triggering the read_many_files tool. This tool is designed to efficiently gather content from multiple files, providing the model with immediate, relevant context without requiring manual file selection.
The read_many_files tool is highly configurable, allowing precise control over which files are included or excluded. Its parameters, defined in the ReadManyFilesParams interface, enable flexible content gathering:

The execute method of the ReadManyFilesTool, implemented in packages/core/src/tools/read-many-files.ts, orchestrates the file discovery and content retrieval. It combines the paths and include patterns, applies exclude patterns (including optional default and .geminiignore patterns), and then uses a globbing utility to find matching files. Each identified file is then read, and its content is concatenated into a single output, providing the model with a comprehensive view of the requested context.

This configurability allows users to precisely define the scope of the context provided to the model, ensuring that the AI operates with the most relevant information for the task at hand.
Project-Specific Instructions with GEMINI.md
Gemini CLI automatically loads GEMINI.md files to provide project-specific context. You can provide detailed instructions and context that the AI will use in every prompt. Here's an example for a TypeScript project based on the repository's own GEMINI.md:
# Gemini CLI Project
- You are an expert in building command-line tools with TypeScript, Node.js, and React (using the Ink library).
- When modifying code, strictly adhere to the existing coding style, formatting (Prettier), and linting rules (ESLint).
- Ensure all new components and hooks are accompanied by corresponding tests.
- The project uses `vitest` for testing.
Interesting Fact: The discovery process is hierarchical. It searches for
GEMINI.mdnot only by traversing up the file system from the current directory to the project root but also by scanning down into subdirectories, as implemented in packages/core/src/utils/memoryDiscovery.ts.

This allows you to have global, project-level, and even component-specific instructions all loaded at once. You can see the full, concatenated context anytime with the /memory show command.
Context Management and Cache Invalidation
A simple caching mechanism would quickly become stale, leading to incorrect inferences based on old code. The Gemini CLI employs a multi-faceted strategy to ensure context is always relevant.
1. Fresh Context on Every Launch
The primary mechanism for preventing stale data is simple: the main context is rebuilt from scratch every time you start Gemini CLI. The loadServerHierarchicalMemory function in packages/core/src/utils/memoryDiscovery.ts performs a fresh scan of the file system for all relevant GEMINI.md files. This ensures that any changes made to your project's context files while Gemini CLI was not running are automatically picked up.

2. User-Controlled In-Session Refresh
If you modify a GEMINI.md file during an active session, you can tell the agent to reload its context using the /memory refresh command. This command, handled by the slashCommandProcessor in packages/cli/src/ui/hooks/slashCommandProcessor.ts, re-runs the entire loadHierarchicalGeminiMemory process, guaranteeing the agent is working with the latest information.

3. Tactical Caching for Tool Correction
The LruCache found in packages/core/src/utils/LruCache.ts is not used for the main prompt context. Instead, it's a tactical, in-session cache used exclusively by the editCorrector utility (packages/core/src/utils/editCorrector.ts).
Its purpose is to cache the results of LLM calls that are made to fix a broken edit command. If the model generates an edit tool call with an old_string that doesn't quite match the file, the editCorrector asks the model to fix it. The LruCache stores the result of that specific correction to avoid asking the model to fix the same broken old_string multiple times within the same session. This cache is discarded when the CLI session ends.
This combination of a fresh context on launch, user-controlled refreshes, and a tactical in-session cache for tool correction ensures that the Gemini CLI operates with relevant and up-to-date information.
4. Implicit API Caching in Action
It's important to distinguish Gemini CLI's local context management from the Gemini API's caching features. The API offers two types of caching, as detailed in the official documentation:
Explicit Caching (
CachedContent): This allows a developer to manually cache large chunks of content and refer to them by a cachenamein subsequent requests.Implicit Caching: This is the default behavior for models like Gemini 2.5 Pro. The API automatically caches the initial parts of a conversation, so only new turns need to be sent in subsequent requests, saving on token usage.
gemini-clitakes advantage of the Gemini API's implicit caching.
The GeminiChat class in packages/core/src/core/geminiChat.ts reconstructs and sends the entire conversation history with each request:

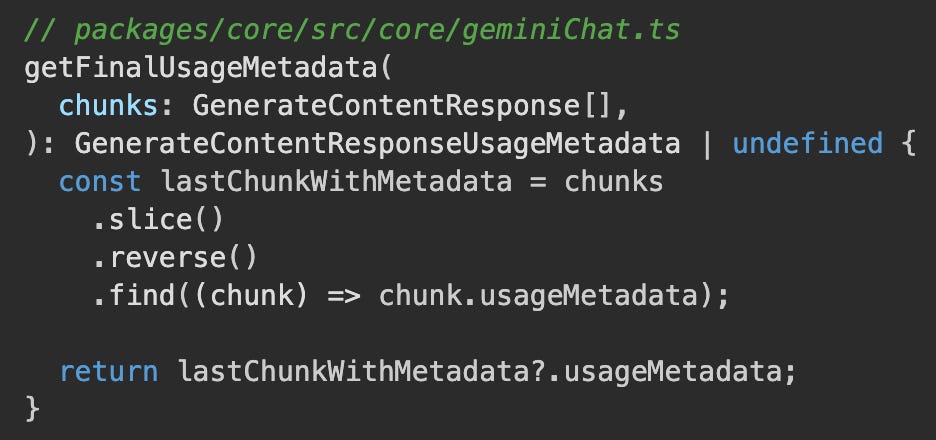
While this may seem inefficient, it is fully compatible with the API's implicit caching. The Gemini backend is designed to recognize the large, common prefix of the conversation history and use its cached version, only charging for the new tokens in the latest turn. Gemini CLI can then inspect the usageMetadata in the API response to see how many tokens were served from the cache.
// Conceptual example of checking usage metadata
const response = await gemini.generateContent(...);
const cachedTokens = response.usageMetadata?.cachedContentTokenCount || 0;
if (cachedTokens > 0) {
console.log(`Served ${cachedTokens} tokens from cache.`);
}
This gives Gemini CLI the best of both worlds: full control over the conversational context for features like /memory refresh, and the token-saving benefits of the API's implicit caching.
How Cached Tokens are Tracked
The tracking of cachedContentTokenCount is handled by the UI layer, which consumes events from the core chat logic. Here's the flow:
API Response: The
usageMetadata, which contains thecachedContentTokenCount, is included in the final chunk of a streaming API response. TheGeminiChatclass inpackages/core/src/core/geminiChat.tsextracts this metadata.
Event Yielding: The
Turnclass, which wrapsGeminiChat, yields aUsageMetadataevent containing this information.UI Consumption: The
useGeminiStreamhook in the UI layer listens for this event and calls theaddUsagefunction from theuseSessionStatshook.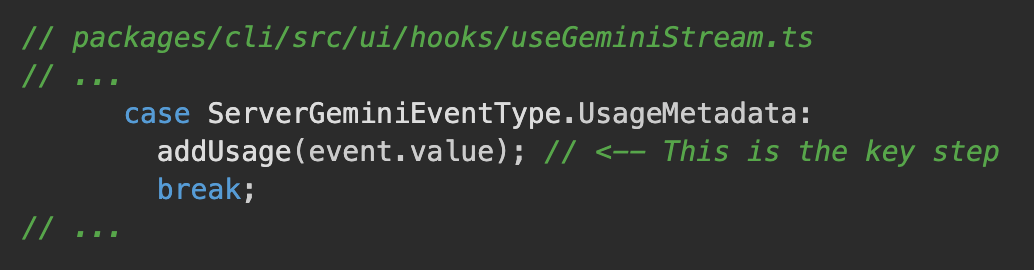
State Management: The
SessionStatsProvidercontext receives this data and updates its running totals, making thecachedContentTokenCountavailable to the UI for display.

Global Preferences with the save_memory Tool
The /memory add slash command calls the save_memory tool. Based on packages/core/src/tools/memoryTool.ts, this tool is designed for persisting natural language facts.


The Hands: A Showcase of Powerful Tools
Surgical Precision: User Confirmation and Modifiable Edits
In Part 1 of this series, we delved into the core mechanics of the edit tool (also known as replace), highlighting its precision and self-correction capabilities. Beyond simply applying changes, the edit tool is designed for user control. Before any modification is written to your files, Gemini CLI presents a clear diff for your review and approval.
This interactive confirmation is managed by the shouldConfirmExecute method within packages/core/src/tools/edit.ts. This method is responsible for calculating the proposed changes and presenting them to you, allowing you to either approve the edit, cancel it, or even open it in your preferred editor to make manual adjustments before execution. This ensures you always have the final say over any code modifications.

This snippet illustrates how the shouldConfirmExecute method generates the visual diff (fileDiff) that you see in the CLI UI, providing transparency and control over the agent's proposed changes.
Interacting with the Environment: The shell Tool
The shell tool provides the Gemini CLI with the capability to execute arbitrary shell commands within the user's environment. This functionality is critical for tasks that extend beyond direct code modification, such as running tests, executing build processes, or invoking linting tools to validate changes.
The implementation of the shell tool, located in packages/core/src/tools/shell.ts, processes a given command string and executes it as a subprocess. It captures both standard output and standard error streams, providing this information back to the model for subsequent decision-making or verification.
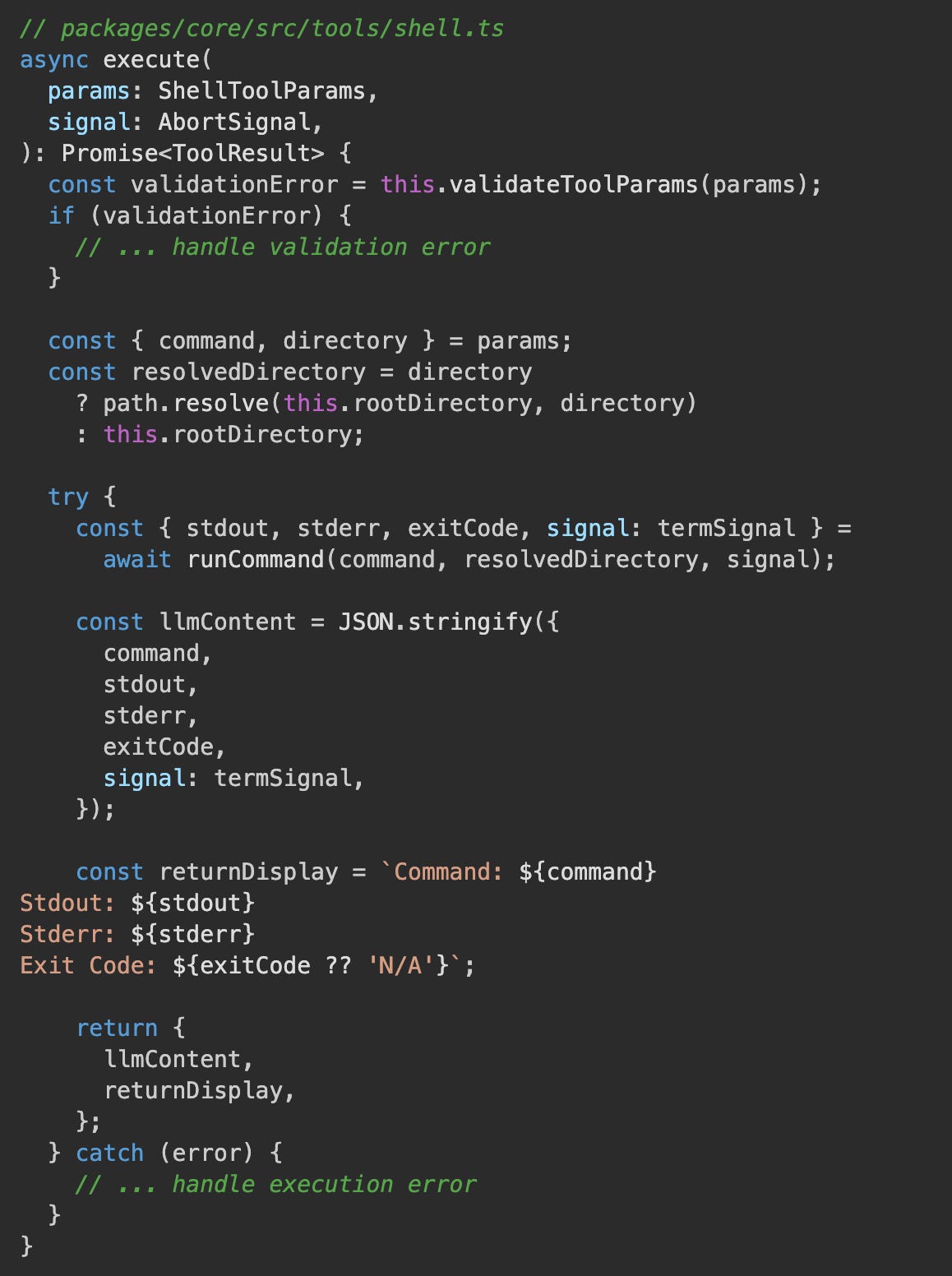
This snippet from the execute method of the ShellTool demonstrates the process: it validates parameters, executes the command using runCommand, and then formats the captured stdout, stderr, and exit code into a ToolResult for the model. This direct interaction with the shell enables Gemini CLI to integrate with existing development workflows.
Next Up: Safety, Control, and Extensibility
In this post, we've explored how Gemini CLI leverages sophisticated memory management and a diverse set of tools to understand and interact with your codebase.
From on-the-fly context with
@commands to persistent global preferences, Gemini CLI is designed to be an intelligent and adaptable assistant.
In Part 1 of this series, we touched upon the core engine. In the next installment, we will dive into the critical aspects of how the Gemini CLI ensures user control through features like shell sandboxing and interactive confirmations. We'll also explore its extensibility, including the Model Context Protocol (MCP), which allows you to integrate your own custom tools and truly make Gemini CLI your own.